A Practical Guide to Building a Seq2Seq Transformer from scratch with PyTorch
Imagine a world where cloud computing hasn’t fully replaced traditional mainframes—a world where, even in 2024, many of the largest companies still rely on decades-old systems. You don’t have to imagine it: you’re living in it. Over 70% of Fortune 500 companies continue to use mainframes and legacy languages like COBOL and PL/1, preferring to maintain and upgrade these systems alongside cloud solutions rather than fully migrating.
In this Jupyter notebook, I’ll demonstrate how I built a sequence-to-sequence (Seq2Seq) machine learning model using PyTorch, focusing on the Transformer architecture. Instead of migrating entire mainframe applications to the cloud, my goal was to train an AI model to act as a transpiler, translating PL/1 code into Kotlin. I’ll walk you through the entire process—from setting up libraries to training and evaluating the model—and finish with a quick demo to showcase the results.
Libraries and setup
I started off by installing the libraries that I would need:
!pip install torch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2
!pip install torchtext==0.8.1
!pip install antlr4-python3-runtime==4.9.2I then imported all the necessary libraries. the Json library is simply used to import the data required to train the model, antlr4 is the backbone of my transpiler, enabling me to parse PL/I code and manipulate its structure with ease, torch from the PyTorch library helped me to build and train my neural networks and finally jinja2 helped simplify code generation thanks to its template engine which ensures a smooth transition between languages.
import json
from antlr4 import *
from pli.PLILexer import PLILexer
from pli.PLIParser import PLIParser
from pli.PLIVisitor import PLIVisitor
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.data import Field, TabularDataset, BucketIterator
from jinja2 import Template
import matplotlib.pyplot as pltThe Transformer Model
I then defined the following Transformer class that encapsulates a custom implementation of a Transformer model – a powerful architecture for sequence-to-sequence tasks – . The class contains quite a few components including embedding layers for source and target sequences, positional embeddings to capture sequence order, and a multi-layer Transformer module. The model utilises dropout for regularisation and employs masks to handle padding and prevent information leakage during training. With all these ingredients, the Transformer class can efficiently process source and target sequences, facilitating tasks like language translation or code generation.
class Transformer(nn.Module):
# Initialises the Transformer model
def __init__(
self,
embedding_size,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
num_heads,
num_encoder_layers,
num_decoder_layers,
forward_expansion,
dropout,
max_len,
device,
):
super(Transformer, self).__init__()
self.src_word_embedding = nn.Embedding(src_vocab_size, embedding_size)
self.src_position_embedding = nn.Embedding(max_len, embedding_size)
self.trg_word_embedding = nn.Embedding(trg_vocab_size, embedding_size)
self.trg_position_embedding = nn.Embedding(max_len, embedding_size)
self.device = device
self.transformer = nn.Transformer(
embedding_size,
num_heads,
num_encoder_layers,
num_decoder_layers,
forward_expansion,
dropout,
)
self.fc_out = nn.Linear(embedding_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
self.src_pad_idx = src_pad_idx
# Generates a mask for the source sequence to handle padding
def make_src_mask(self, src):
src_mask = src.transpose(0, 1) == self.src_pad_idx
# (N, src_len)
return src_mask.to(self.device)
# Forward pass of the Transformer model
def forward(self, src, trg):
src_seq_length, N = src.shape
trg_seq_length, N = trg.shape
src_positions = (
torch.arange(0, src_seq_length)
.unsqueeze(1)
.expand(src_seq_length, N)
.to(self.device)
)
trg_positions = (
torch.arange(0, trg_seq_length)
.unsqueeze(1)
.expand(trg_seq_length, N)
.to(self.device)
)
embed_src = self.dropout(
(self.src_word_embedding(src) + self.src_position_embedding(src_positions))
)
embed_trg = self.dropout(
(self.trg_word_embedding(trg) + self.trg_position_embedding(trg_positions))
)
src_padding_mask = self.make_src_mask(src)
trg_mask = self.transformer.generate_square_subsequent_mask(trg_seq_length).to(
self.device
)
out = self.transformer(
embed_src,
embed_trg,
src_key_padding_mask=src_padding_mask,
tgt_mask=trg_mask,
)
out = self.fc_out(out)
return outData preparation and tokenization
For the model to understand and be able generate the wanted text, I had to start by tokenizing my input data. I then also set up my datasets which allowed me to manage my training and testing data more efficiently
Tokenize
I defined a simple tokenizer that splits a string into tokens based off of whitespace. It then creates two Field objects with some specifications and finally I instantiated a dictionary that maps field names to tuples to be used later to specify how to load and process my data.
import torchtext.data as data
tokenizer = lambda x: x.split()
pli = data.Field(sequential=True, use_vocab=True, tokenize=tokenizer, lower=True, init_token="<sos>", eos_token="<eos>")
ktl = data.Field(sequential=True, use_vocab=True, tokenize=tokenizer, lower=True, init_token="<sos>", eos_token="<eos>")
fields = {'pli': ('p', pli), 'ktl': ('k', ktl)}Splits
To create separate datasets for training and testing, I used the TabularDataset module from the torchtext.data package. The data is loaded from JSON files located in my ‘data’ directory. I then had to specify the format of the data as JSON and define the fields to be extracted from said files using the fields parameter.
train, test = data.TabularDataset.splits(
path='data',
train='train.json',
test='test.json',
format='json',
fields=fields,
)Vocab
I then built my vocabulary, building a vocabulary means creating a dictionary that maps each unique word in the dataset to a unique index. This process is crucial for natural language processing tasks as it allows machine learning models to represent the words that I gave it as input and the words it outputs as numerical values, which it can process and understand. In this case, I built 2 vocabularies, one for the PL/I (pli) dataset and the other for Kotlin (ktl) dataset, this ensured that the model had a predefined set of words it could understand and process during training and inference
pli.build_vocab(train, max_size=10000, min_freq=1)
ktl.build_vocab(train, max_size=10000, min_freq=1)Translate and transpile
I then defined a 2 key functions that will be very important to train the model and also be able to see some concrete results after training.
Translate
Firstly I defined a translate_sequence function. The function tokenizes an input sentence, adds < sos > ( start of sequence ) and < eos > ( end of sequence ) tokens at the beginning and end respectively, converts these tokens to indices using the vocabulary from the pli field, converts these indices to a PyTorch tensor – simply to comply with the library – and then it iteratively predicts the next token in the translated sequence using the trained model until either an < eos > token is predicted or the maximum sequence length is reached. After all of this, it converts the predicted output indices back to tokens using the vocabulary of the Kotlin field and returns the translated sentence, removing the start token < sos > as this token is only used to signal to the model to start generation and is not part of the actual translated text that I wanted back.
def translate_sequence(sentence, pli, ktl, device, max_length=50):
if type(sentence) == str:
tokens = [token.lower() for token in sentence.split()]
else:
tokens = [token.lower() for token in sentence]
# Add <SOS> and <EOS> in beginning and end respectively
tokens.insert(0, pli.init_token)
tokens.append(pli.eos_token)
# Iterate each languae token and convert to an index
text_to_indices = [pli.vocab.stoi[token] for token in tokens]
# Convert to Tensor
sentence_tensor = torch.LongTensor(text_to_indices).unsqueeze(1).to(device)
outputs = [ktl.vocab.stoi["<sos>"]]
for i in range(max_length):
trg_tensor = torch.LongTensor(outputs).unsqueeze(1).to(device)
with torch.no_grad():
output = model(sentence_tensor, trg_tensor)
best_guess = output.argmax(2)[-1, :].item()
outputs.append(best_guess)
if best_guess == ktl.vocab.stoi["<eos>"]:
break
translated_sentence = [ktl.vocab.itos[idx] for idx in outputs]
# remove start token
return translated_sentence[1:]Transpile
I then defined a second function transpile_sequence. This function retrieves the code tokens and context data from my input dictionary. It then initialises an empty list to store the transpiled code with proper indentation. It then iterates through the tokens, adjusting the indentation level based on curly braces {} encountered in the code. After iterating through all the tokens, the function finishes by joining the transpiled code with proper spacing and correctly renders it using contextual data. To finish everything off, it returns the transpiled code with the updated indentation.
def transpile_sequence(translated, level):
tokens = translated["code"]
data = translated["context"]
lint = []
for t in tokens:
spacer = "".rjust(level * 4)
if t == "{":
level += 1
elif t == "}" and level > 0:
level -= 1
spacer = "".rjust(level * 4)
if t != "<eos>":
lint.append(spacer + t)
code = " ".join(lint)
t = Template(code)
return t.render(data), levelSpecifics
Before I defined the final parameters and actually trained my model I had a few extra functions to define.
This remove_eos function removes all < eos > tokens and then concatenate the remaining tokens into a single string
def remove_eos(witheos):
noeos = []
for w in witheos:
if w != '<eos>':
noeos.append(w)
return " ".join(noeos)And then, the following functions, save_checkpoint and load_checkpoint, are essential for simply saving and loading the state of our model during training and inference.
def save_checkpoint(state, filename="checkpoint.pth.tar"):
print("=> Saving checkpoint")
torch.save(state, filename)
def load_checkpoint(checkpoint, model, optimizer):
print("=> Loading checkpoint")
model.load_state_dict(checkpoint["state_dict"])
optimizer.load_state_dict(checkpoint["optimizer"])Training
Hyperparameters
Before training the model I started by defining some model hyperparameters that help the model process and transform my input data. I also defined some training hyperparameters that regulate the training process.
# ready to define everything we need for training our Seq2Seq model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
load_model = True
save_model = True
# Model hyperparameters
src_vocab_size = len(pli.vocab)
trg_vocab_size = len(ktl.vocab)
embedding_size = 512
num_heads = 8
num_encoder_layers = 6
num_decoder_layers = 6
dropout = 0.10
max_len = 100
forward_expansion = 4
src_pad_idx = ktl.vocab.stoi["<pad>"]
global level
# Training hyperparameters
num_epochs = 300
learning_rate = 3e-4
batch_size = 32
training_losses = []Model Initialization and Training Setup
To train a Transformer model, I had to initialized the following: model, optimizer, scheduler, and criterion. I also created iterators for the training and test datasets that facilitate data management, improve computational efficiency and improve the overall training process’s effectiveness.
train_iterator, test_iterator = BucketIterator.splits(
(train, test),
batch_size=batch_size,
sort_within_batch=True,
sort_key=lambda x: len(x.p),
device=device,
)
model = Transformer(
embedding_size,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
num_heads,
num_encoder_layers,
num_decoder_layers,
forward_expansion,
dropout,
max_len,
device,
).to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, factor=0.1, patience=10, verbose=True
)
pad_idx = ktl.vocab.stoi["<pad>"]
criterion = nn.CrossEntropyLoss(ignore_index=pad_idx)Training loop
Phew, I finally got to actually training. I defined a custom training loop to meet my specific needs. This loop fetches batches of data using the training_iterator. Input and target sequences are transferred to the appropriate device (CPU or GPU). The model is trained using forward and backward passes. I applied Gradient clipping to prevent exploding gradients and I used an optimizer to update the models parameters based on the computed gradients. After training, I evaluated the model’s performance using some example pli sequences and translating them to Kotlin using my freshly trained model. Finally I used matplotlib to visualise the training loss and saved the trained model as a checkpoint to able to use later.
if __name__ == '__main__':
for epoch in range(num_epochs):
model.eval()
# little bit of output to check the progress
if epoch % 50 == 0:
print(f"[Epoch {epoch} / {num_epochs}]")
# Iterate over the dataset and extract PLI sequences
sentences = [
{'pli': ['PROCEDURE', 'MAIN', '{{type0}}', '{{type1}}'],
'context': {'type0': 'Array', 'type1': 'String'}},
{'pli': ['DO'], 'context': {}},
{'pli': ['END'], 'context': {}}
]
print(f"Translated example sentence:")
level = 0
for s in sentences:
translated = translate_sequence(
s['pli'], pli, ktl, device, max_length=50
)
transpiled, level = transpile_sequence({
'code': translated,
'context': s['context']
}, level)
print(f"{transpiled}")
last_5_losses = training_losses[-5:]
print("Last 5 training losses:", last_5_losses)
model.train()
losses = []
for batch_idx, batch in enumerate(train_iterator):
# Get input and targets and get to cuda
inp_data = batch.p.to(device)
target = batch.k.to(device)
# Forward
output = model(inp_data, target[:-1, :])
output = output.reshape(-1, output.shape[2])
target = target[1:].reshape(-1)
optimizer.zero_grad()
loss = criterion(output, target)
losses.append(loss.item())
# Back prop
loss.backward()
# Clip to avoid exploding gradient issues, makes sure grads are
# within a healthy range
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)
# Gradient descent step
optimizer.step()
training_losses.append(loss.item())
mean_loss = sum(losses) / len(losses)
scheduler.step(mean_loss)
# Print the final epoch
print(f"[Epoch {num_epochs} / {num_epochs}]")
# Iterate over the dataset and extract PLI sequences
for s in sentences:
translated = translate_sequence(
s['pli'], pli, ktl, device, max_length=50
)
transpiled, level = transpile_sequence({
'code': translated,
'context': s['context']
}, level)
print(f"{transpiled}")
# Translate and transpile here if needed
last_5_losses = training_losses[-5:]
print("Last 5 training losses:", last_5_losses)
plt.plot(training_losses, label='Training Loss')
plt.xlabel('Iterations')
plt.ylabel('training_losses')
plt.title('Training Loss Over Iterations')
plt.legend()
plt.show()
if save_model:
checkpoint = {
"state_dict": model.state_dict(),
"optimizer": optimizer.state_dict(),
}
save_checkpoint(checkpoint)[Epoch 0 / 300]
Translated example sentence:
<pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
<pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> () () <pad> <pad> <pad> <pad>
<pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad> <pad>
Last 5 training losses: []
[Epoch 50 / 300]
Translated example sentence:
fun main (args: Array<String>)
{
}
Last 5 training losses: [0.11536741256713867, 0.13401655852794647, 0.09288042783737183, 0.0880018100142479, 0.0810730904340744]
[Epoch 100 / 300]
Translated example sentence:
fun main (args: Array<String>)
{
}
Last 5 training losses: [0.002143696416169405, 0.0021836746018379927, 0.002142140408977866, 0.0020195324905216694, 0.0023125687148422003]
Epoch 125: reducing learning rate of group 0 to 3.0000e-05.
Epoch 145: reducing learning rate of group 0 to 3.0000e-06.
[Epoch 150 / 300]
Translated example sentence:
fun main (args: Array<String>)
{
}
Last 5 training losses: [0.0009272661409340799, 0.0009802684653550386, 0.0009581581107340753, 0.0009119620081037283, 0.0009031783556565642]
Epoch 156: reducing learning rate of group 0 to 3.0000e-07.
Epoch 167: reducing learning rate of group 0 to 3.0000e-08.
Epoch 178: reducing learning rate of group 0 to 3.0000e-09.
[Epoch 200 / 300]
Translated example sentence:
fun main (args: Array<String>)
{
}
Last 5 training losses: [0.0009122670162469149, 0.0009905740153044462, 0.0010367712238803506, 0.0011590280337259173, 0.0010337315034121275]
[Epoch 250 / 300]
Translated example sentence:
fun main (args: Array<String>)
{
}
Last 5 training losses: [0.001014587003737688, 0.0008746228413656354, 0.001056693377904594, 0.0011161871952936053, 0.001087463111616671]
[Epoch 300 / 300]
fun main (args: Array<String>)
{
}
Last 5 training losses: [0.0009633959271013737, 0.0010461953934282064, 0.0010198841337114573, 0.0018401391571387649, 0.0009006673935800791]
=> Saving checkpoint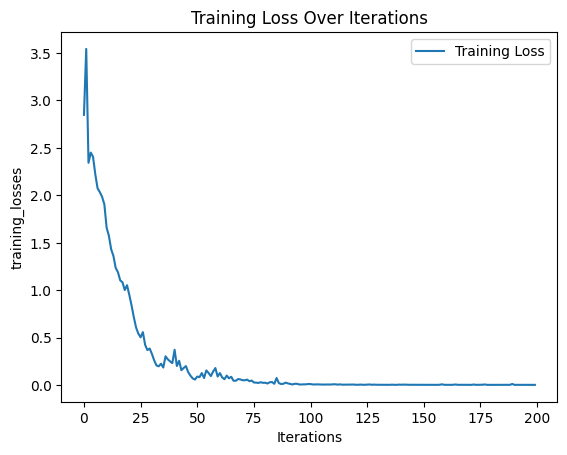
Running the Transpiler
And as I promised at the start of this article as a little bonus I can show you a real example of how my AI transpiller works.
I defined a run_model function that processes a PL/1 file. I then loaded my previously trained ( pre-trained ) model and its optimiser. I set up a lexer and parser for the PL/1 code using ANTLR4. I generated a dataset from this parsed code using a visitor pattern – which iterates through the AST (Abstract Syntax Tree) generated by the parser – . Next, for each statement in the PL1 code, I translated and transpiled each statement in the PL1 code into Kotlin – of course – using my Seq2Seq model. The function then accumulates and prints the Kotlin code as output. This function essentially just automates the process of translating our PL1 code to Kotlin
def run_model(filename):
with open(filename, 'r') as file:
original_code = file.read()
print("PL1:")
print(original_code)
print()
load_checkpoint(torch.load("checkpoint.pth.tar"), model, optimizer)
# Lexer setup
input_stream = FileStream(filename)
lexer = PLILexer(input_stream)
stream = CommonTokenStream(lexer)
# Parser setup
parser = PLIParser(stream)
tree = parser.program()
# Dataset generation
visitor = PLIVisitor()
statements = visitor.visit(tree)
# Accumulate transpiled sequences
transpiled_code = ""
level = 0
for s in statements:
translated = translate_sequence(
s["pli"], pli, ktl, device, max_length=50
)
transpiled, level = transpile_sequence({
'code': translated,
'context': s['context']
}, level)
transpiled_code += transpiled+ "\n"
# Print the entire block of transpiled code
print("KTL:")
print("\n" + transpiled_code)
# Example usage:
filename = "FIB.PLI"
run_model(filename)PL1:
Factorial: proc options (main);
dcl (n,result) fixed bin(31);
n = 5;
result = Compute_factorial(n);
end Factorial;
/***********************************************/
/* Subroutine */
/***********************************************/
Compute_factorial: proc (n) returns (fixed bin(31));
dcl n fixed bin(15);
if n <= 1 then
return(1);
return( n*Compute_factorial(n-1) );
end Compute_factorial;
=> Loading checkpoint
KTL:
fun main (args: Array<String>)
{
var n : Int
var result : Int
n = 5
result = compute_factorial(n)
}
fun compute_factorial(n : Int) : Int
{
if(n<=1)
{
return 1
}
return n*compute_factorial(n-1)
}
Conclusion
In this article, I navigated two challenging tasks: setting up and training my own AI model—an intimidating feat for a newcomer to AI—and then using the trained model to translate an old programming language into a modern one. These accomplishments reflect both the steep learning curve and the excitement of tackling new technical frontiers. I hope I proved to anyone reading this today that even daunting projects like this one can be made approachable with the right mindset and tools.
For those interested in further exploring machine translation using AI models, I have written a follow up article where I simplify this entire process by utilising frameworks and the Hugging Face API. Go give it a read: Fine-tuning a pre-trained Sequence to Sequence model for code translation